国家工商总局最近公布了抽查了各家网购平台的抽检结果,92件样品38件非正品,而手机正品率更只有28%。央视报道的节目中说到,“9个电商平台中,只有两家没有被检出销售假冒或质量不合格的商品”。 这个结果挺 ...
国家工商总局最近公布了抽查了各家网购平台的抽检结果,92件样品38件非正品,而手机正品率更只有28%。央视报道的节目中说到,“9个电商平台中,只有两家没有被检出销售假冒或质量不合格的商品”。
这个结果挺要命,不到6成的正品率,叫大家怎么安心“剁手”。不过细心的人也发现了一个问题,9家网购平台上的商品多的数不清,总共抽取92件,平均每家抽取10件商品检测,得到的结果能否代表真实情况?并且,“非正品”也不等于“假冒”或是“质量不合格”。再一看这次抽检的详情表,更是下巴都掉了下来。
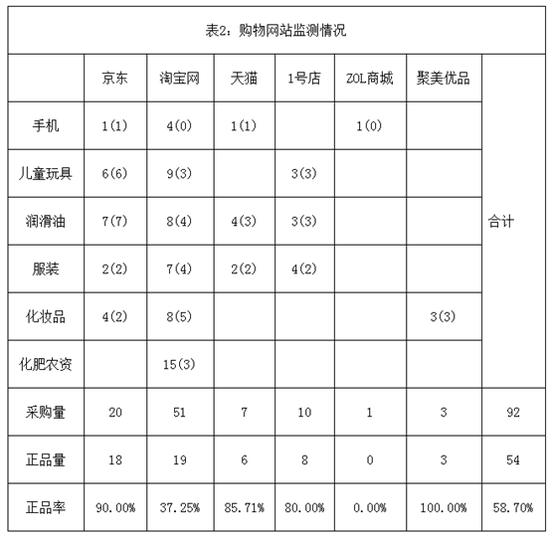
ZOL商城欲哭无泪,总共就抽取了1个商品,不幸还是非正品,一下全军覆没。如果是一个普通的消费者,他当然可以说:“随便买个东西就是假的,你家太差了!”但一个权威调查机构也这样,未免草率。
那么,一次有说服力的抽检应该是什么样的?
随便≠随机
 图片来源:sunlogistics.fr
图片来源:sunlogistics.fr对于商品质量抽检而言,一个消费者任意网购一件商品回来,检测是否正品或者是否符合国家标准,是否也能算作一次质量检测?当然。他毕竟完成了一次抽样。但是,这种行为叫做非概率抽样,样本总是限于主观和容易获取的部分。既不能确定抽样误差,也不能通过统计数据推断整体。
非概率抽样的方法有很多种,“先生耽误您两分钟”的街头拦人发调查问卷是个典型——这属于方便抽样——选取最容易抽取的样本。其他还有比如判断抽样,尽管总体涉及到所有类别的所有商品,但仅通过个人判断,选择数个商品来描述整个样本。
这种粗略和前期的探索,主要目的是用较低的成本做近似的估计。优点是方便快捷省事,缺点是……缺点很多。
想要客观地对总体的某些特征做出具备一定可靠性的推论,概率抽样中最正式的抽样方法——简单随机抽样——是个好选择。随机抽样要求总体中每个个体拥有相同的被抽中概率。当总体非常大时,做到这点非常困难。
例如淘宝商品类别繁多,数量更加庞大。跑一遍人家的数据库,随机抽取太不现实。这种情况下,对简单随机抽样做出改进和简化就很有必要。
系统抽样是一种改进方法,以固定的间隔每隔若干个体抽取一个样本。另一种改进方法是采用分层抽样,按某种特征将要个体划分成不同的层,然后按照简单随机抽样方法从每一个层里抽取足够的个体。
“层”就是某种划分方法,例如人可以分成男、女两层。每个层都是总体的一个子集,各层之间互相独立。只有划分出具有代表性的层后,抽样才有意义。相比随便点开一家店铺购买一些商品用于检测,根据信用等级等指标,先选出有代表性的商铺,然后在商铺中随机挑选商品,是个更好一些的抽样方法。
不同的样本能混为一谈吗?
 图片来源:webseoanalytics.com
图片来源:webseoanalytics.com再说回到这次工商总局发布的监测结果,不同的样本其实不具备可比性。京东的自营和淘宝卖家,一个是京东自己卖,一个是所有人都来卖。就像单纯地对比癌症的发病率高于心脏病的发病率,既不能得出癌症比心脏病更可怕的结论,也不能说明人们应该预防癌症多于预防心脏病。
除此之外,得到每个电商平台的正品率还算好说,直接合计得出一个总体的正品率,却没有道理。不同电商在经营模式、消费者习惯等等各个环节都有很多差异。在不能确保其他条件相同的情况下,单纯的累加只会浪费人们的注意力。举个例子,男性也会得乳腺癌,但远比女性低,非要计算全人类得乳腺癌的概率其实没什么意义。
另一方面,工商总局发布的监测情况表遍布统计陷阱,比如化肥这一类别的质量检测,去除这一项,淘宝的正品率一下从37.25%飞升到44.44%,但是淘宝上的化肥商品恐怕很难占到总量的7%。更不要说其他电商平台均未抽取化肥这一商品了。
再比如,让我们粗略地用京东PK天猫一次。按照工商总局发布的监测情况表,京东抽取20个样本,正品量18,正品率90.00%;天猫抽取7个样本,正品量6,正品率85.71%。近5%的差别还算明显。但是按照这个比率,如果天猫抽取21个样本,正品量是18。这个时候,你还会觉得京东相比天猫有明显的正品优势吗?
最少抽取多少个样本,才算样本充分?
是的,样本量的不一致,带来了很多误解和不准确。抽取1个样本全是假的或者3个样本全是正品,就推断该平台正品率0%或者100%实在过于鲁莽。
那么,抽样调查中需要多少样本才算证据充分呢?实际上,统计学里,具备相应置信度的样本量是可以计算的。
抽样方法本身就会引起误差。在总体中随机抽取样本,样本均值x是总体均值μ的偏差就是抽样误差(E=μ-x)。这个误差的分布是符合标准正态分布的。
面对一个数量庞大的总体,样本量也要足够多(>30)时,可以用如下公式可以估算吃需要抽取的样本量:
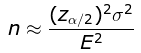
n:样本量
σ2:方差,抽样个体值和整体均值之间的偏离程度,抽样数值分布越分散方差越大,需要的采样量越多
E:为抽样误差(可以根据均值的百分比设定
Zα/2:置信度,置信度越高需要的样本量越多;95%置信度比90%置信度需要的采样量多40%
由此可见,在保证一定置信度(样本某测量值的可信程度)的情况下,如果要将误差控制得越小,所需的样本量则越大。样本量太少,误差便会很大,对总体真实情况的推断和估计也就很难准确了。
可靠的结论是要花大钱的
话说回来,你当然不能说这次抽检没有意义,它至少说明网购有风险。毕竟即便只有一件不符合国家规定的商品也是有问题的,一旦发现就应当处理。
但如果要说这样的抽检结果,可以反映网购平台的整体状况,还相去甚远。如果成本投入少,人力物力时间也不充分,不管是在科学、社会还是经济领域,想得到一个可靠的结论都不太现实。毕竟大型的调研并非三两个人一朝一夕能完成,这需要大把的金钱和时间。实际上,国家对于计数抽样检验有一套复杂而严密的标准化流程,即GB2828和GB2829。
这并非是说普通人不要去尝试此类调查研究,而是说条件有限的情况下,想得到一个相对可靠的研究结果,完善调查方法尤为重要。这一点,则是人人都可以去努力和实现的。
监督方式防骗必读生意骗场亲历故事维权律师专家提醒诚信红榜失信黑榜工商公告税务公告法院公告官渡法院公告
个人信用企业信用政府信用网站信用理论研究政策研究技术研究市场研究信用评级国际评级机构资信调查财产保全担保商帐催收征信授信信用管理培训
华北地区山东山西内蒙古河北天津北京华东地区江苏浙江安徽上海华南地区广西海南福建广东华中地区江西湖南河南湖北东北地区吉林黑龙江辽宁西北地区青海宁夏甘肃新疆陕西西南地区西藏贵州云南四川重庆
